Da ich trotz Dokumentation und Suche im Internet oftmals immer wieder Infos neu erarbeitet habe, dient mir dieser Blogeintrag auf der einen Seite als Doku und hilft auf der anderen Seite vielleicht Dir. Viel Spaß beim einrichten und immer gut überlegen, ob die Optionen für Deinen Proxmox Server sinnvoll sind!
Generelle Einstellungen
Timezone
Damit möglichst alles in der richtigen Zeitzone läuft, setze ich generell mit folgenden Befehlen bei meinen Linux-Systemen die Zeitzone:
timedatectl set-timezone Europe/Berlin timedatectl systemctl enable --now systemd-timesyncd
Automatische Updates einspielen
Durch unattended-upgrades, können wichtige Update automatisch eingespielt werden. Dafür reichen die folgenden Befehle:
apt update && apt upgrade -y # Paketlisten aktualisieren und alle verfügbaren Updates installieren apt install -y unattended-upgrades # Paket für automatische Sicherheitsupdates installieren echo unattended-upgrades unattended-upgrades/enable_auto_updates boolean true | debconf-set-selections # Automatische Updates vorab aktivieren (per debconf) dpkg-reconfigure -f noninteractive unattended-upgrades # Einstellungen übernehmen – ohne Benutzerabfrage systemctl status unattended-upgrades # Zeigt den Dienststatus an
Tuning des Proxmox-Host
In der Datei /etc/sysctl.d/99-sysctl.conf können folgende Parameter die Leistung positiv beeinflussen:
### Systemoptimierung für Proxmox-Host mit viel RAM und Containern ### # Diese Einstellungen wurden für hohe Netzwerklast, viele VMs/LXCs und RAM-optimierten Betrieb angepasst. ###################################### # Speicher- und Swap-Management ###################################### # SWAP erst nutzen, wenn RAM fast voll ist vm.swappiness = 10 # Caches länger im RAM behalten, nützlich für Datenbank-/Dateisystem-Performance vm.vfs_cache_pressure = 50 # Virtuellen Speicher über die physische RAM-Grenze hinaus erlauben (nützlich für Container) vm.overcommit_memory = 1 # Dirty Pages: Daten werden nach max. 180s aus RAM auf Disk geschrieben vm.dirty_expire_centisecs = 18000 vm.dirty_writeback_centisecs = 3000 # Bei 10 % RAM werden Dirty Pages geschrieben (bei 5 % wird begonnen) vm.dirty_ratio = 10 vm.dirty_background_ratio = 5 ###################################### # Datei-/Dateisystem-Limits ###################################### # Mehr offene Files erlauben fs.file-max = 2097152 # Viele gleichzeitige Datei-Watcher (z. B. Docker, node.js, Syncthing) fs.inotify.max_user_watches = 1048576 fs.inotify.max_user_instances = 16777216 fs.inotify.max_queued_events = 32000 ###################################### # Netzwerkoptimierungen ###################################### # IPv6 deaktivieren (falls nicht benötigt) net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1 # TCP: Schnellerer Verbindungsaufbau und Abbau net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_retries2 = 5 net.ipv4.tcp_fin_timeout = 10 # Keepalive-Einstellungen (stabilere TCP-Verbindungen bei z. B. MQTT, Websocket) net.ipv4.tcp_keepalive_time = 600 net.ipv4.tcp_keepalive_intvl = 15 net.ipv4.tcp_keepalive_probes = 5 # Verbindungen im TIME_WAIT-Status schneller abbauen net.ipv4.tcp_max_tw_buckets = 2000000 # Netzwerkgeräte: Größere Warteschlange vor Paketverlust net.core.netdev_max_backlog = 250000 # TCP-Empfangs- und Sendepuffer für hohe Bandbreiten net.core.rmem_max = 67108864 net.core.wmem_max = 67108864 # TCP-Buffer-Autotuning optimieren net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216 # Aktiviert dynamische TCP-Fenstergrößen für bessere Performance net.ipv4.tcp_window_scaling = 1 # SYN-Flood-Schutz aktivieren net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_syn_retries = 2 net.ipv4.tcp_synack_retries = 2 net.ipv4.tcp_orphan_retries = 2 # Viele gleichzeitige Verbindungen erlauben net.core.somaxconn = 256000 net.ipv4.tcp_max_syn_backlog = 40000 # Mehr lokale Ports verfügbar machen net.ipv4.ip_local_port_range = 10000 60000 # Nachbarschafts-Cache für viele gleichzeitige Clients (z. B. bei VMs) net.ipv4.neigh.default.gc_thresh1 = 1024 net.ipv4.neigh.default.gc_thresh2 = 2048 net.ipv4.neigh.default.gc_thresh3 = 4096 # Bessere Paketplanung, reduziert Latenzen (Kernel 4.x+) net.core.default_qdisc = fq_codel net.ipv4.tcp_congestion_control = bbr # TCP-Verhalten: Keine langsame Verbindung nach Idle-Zeit net.ipv4.tcp_slow_start_after_idle = 0 net.ipv4.tcp_low_latency = 1 # Schutz gegen bestimmte TCP-Angriffe net.ipv4.tcp_challenge_ack_limit = 9999 net.ipv4.tcp_rfc1337 = 1 net.ipv4.tcp_sack = 0 net.ipv4.tcp_mtu_probing = 0 # UDP Performance (z. B. bei DNS oder NFS) net.ipv4.udp_rmem_min = 8192 net.ipv4.udp_wmem_min = 8192 # Längere Unix-Socket-Warteschlangen (z. B. bei Docker-Socket) net.unix.max_dgram_qlen = 1024 # Conntrack für viele Verbindungen (z. B. viele Docker-Container) net.netfilter.nf_conntrack_max = 1048576 net.nf_conntrack_max = 1048576 ###################################### # Sicherheit & Sonstiges ###################################### # Unprivilegiertes BPF deaktivieren (Sicherheitsmaßnahme) kernel.unprivileged_bpf_disabled = 1 # IPv4/IPv6 Fragmentierungsgrenzen für bessere Performance net.ipv4.ipfrag_high_thresh = 8388608 net.ipv4.ipfrag_low_thresh = 196608 net.ipv6.ip6frag_high_thresh = 8388608 net.ipv6.ip6frag_low_thresh = 196608 # Scheduler: Prozesse nicht zu oft zwischen CPUs verschieben kernel.sched_migration_cost_ns = 5000000 kernel.sched_autogroup_enabled = 0
Final werden die Einstellungen mit diesem Befehl umgesetzt:
sysctl --system
Vom Prinzip her kann man diese auch in den LXCs setzen, die meisten werden aber vom Host vorgegeben und sind somit sowieso wirkungslos. Bei VMs greifen diese Änderungen wiederum.
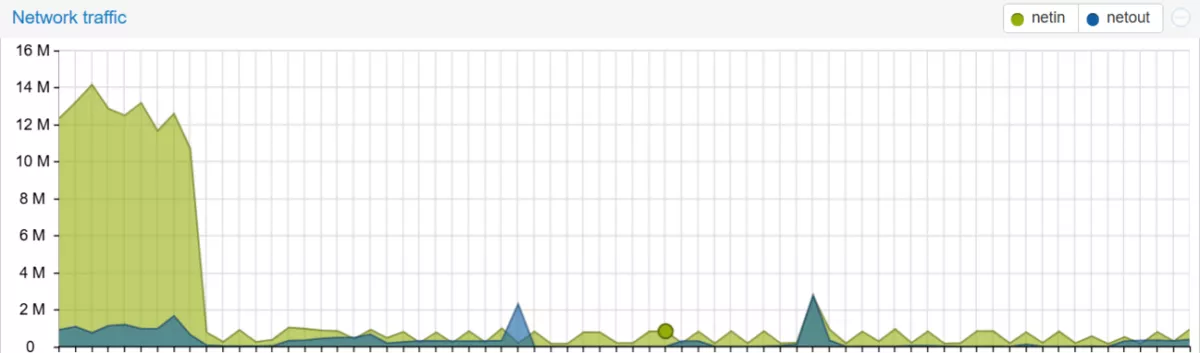
Wie sich das beim Netzwerkverkehr auswirkt, könnt Ihr bei folgendem Screenshot nachvollziehen:
Tuning des I/O Shedulers
Die folgenden Einstellungen stellen den I/O Sheduler auf mq-deadline. Diese Option bedeutet, dass er schnel, fair und planbar Schnell, fair, planbar, besonders gut für SSDs/NVMe
echo 'ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/scheduler}="mq-deadline"' > /etc/udev/rules.d/60-ioscheduler.rules
udevadm control --reload
Tuning LXCs und VMs
Mein Proxmox System habe ich recht üppig mit RAM bestückt (70GB) und dieser wird, trotz diverser LXCs und VMs gar nicht so ausgiebig genutzt. Außerdem kommt es hier und da zu IO-Zeiten > 20. Daher wollte ich das System mal etwas feintunen und werde diesen Blogbeitrag fortlaufend pflegen…
SWAP deaktivieren
Bei Systemen mit ausreichend RAM, kann mittels dem Parameter vm.swappines das SWAP verhalten beeinflusst werden. Ich habe mich aber dazu entschieden, den SWAP zu deaktivieren:
swapoff -a # Deaktiviert alle aktiven Swap-Devices (Swap-Partitionen, -Dateien, ZRAM usw.) systemctl mask swap.target # Verhindert dauerhaft, dass Swap beim Boot aktiviert wird
/etc/systemd/journald.conf
In dieser Datei wird konfiguriert, wie der Journal-Dienst arbeitet, wo die Logs gespeichert werden usw. Die Logs wurden mehrere GB groß, so dass ich hier Handlungsbedarf hatte. Meine erste Überlegung war, einfach alles in den RAM zu packen, mich interessieren im Regelfall nur aktuelle Log Daten und das habe ich so gelöst:
[Journal] Storage=auto # Speichert Logs persistent (Festplatte), wenn /var/log/journal existiert, sonst nur im RAM. SystemMaxUse=1024M # Maximaler Speicherplatz, den alle Journale auf der Festplatte zusammen nutzen duerfen. SystemMaxFileSize=10M # Maximale Groesse einer einzelnen Journal-Datei (danach wird rotiert). MaxRetentionSec=14day # Logs werden maximal 14 Tage lang behalten, danach automatisch geloescht. Compress=yes # Komprimiert aeltere Logs, um Speicherplatz zu sparen. Storage=volatile # Speichert Logs nur im RAM (/run/log/journal), gehen beim Reboot verloren.
Damit die Einstellungen greifen ist ein Neustart des Service notwendig:
systemctl restart systemd-journald
Wenn Du allerdings nur mal kurz aufräumen willst, geht das mit diesen Befehlen:
journalctl --vacuum-size=100M # Bereinigt die Logs auf max. 100MB journalctl --vacuum-time=7d # Loescht alle Einträge aelter als 7 Tage
Logs & Cache generell in den RAM
Generell Logs in den RAM zu legen hat seine Vor- und Nachteile. Z.B. Kernel-Crashes können nicht mehr so einfach nachvollzogen werden. Daher überlegt Euch gut, auf welchen Systemen das Sinn macht. Beim Cache ist das mMn. wiederum unbedenklich. Um das generell für beides zu aktivieren, kann man folgendes in die /etc/fstab schreiben:
tmpfs /var/log tmpfs defaults,noatime,nosuid,size=1024M 0 0 # /var/log im RAM speichern (max. 1024MB), kein Zugriff auf Dateiattribute (noatime), keine SUID-Bits tmpfs /var/tmp tmpfs defaults,noatime,nosuid,size=2G 0 0 # /var/tmp in RAM legen (max. 2GB) tmpfs /tmp tmpfs defaults,noatime,nosuid,size=2048M 0 0 # /tmp ins RAM legen (max. 2048MB), schneller Zugriff, keine dauerhafte Speicherung
Nach dem speichern kann man das mit diesen Befehlen aktivieren und sich anzeigen lassen:
systemctl daemon-reload # Laedt die Service-Dateien neu ein mount -a # Setzt das Mounting aus der /etc/fstab um df -h | grep tmpfs # Zeigt den belegten Speicher in den RAM-Mounts an
…